Le partage de fichiers d'ordinateur à ordinateur
existe depuis une trentaine d'années, quand Arpanet
permettait aux universitaires américains d'échanger
leurs travaux. L'architecture dite peer to peer, ou chaque
ordinateur est client et serveur a été
popularisée par Napster. Ce système
n'a cessé d'évoluer, et évolue encore. Le
partage de fichiers Mp3, vidéo, programmes...entre internautes,
est possible entre particuliers, grâce à la compression
des données numériques. L'audio est compressé
en format Mp3 (30 Mo deviennent environ 3 Mo), la vidéo
en divx. Pour partager (et recevoir) il faut installer
un logiciel qui vous permettra de mettre votre ordinateur
en réseau avec la communauté qui utilise ce logiciel.
Plusieurs logiciels peuvent être installés sur la
même machine.
>
eMule utilise le réseau et les serveurs eDonkey
site officiel français
eMule
Logiciels : iMesh - Attention : à l'installation, désactiver certaines options cochées par défaut, sinon vous installerez des logiciels inutiles (espions!) Gator...
>
BitTorrent,
une nouvelle conception du peer to peer.
> commment graver avec Néro?
Le peer-to-peer, littéralement "d'égal
à égal", ou "de pair à pair",
est un système d'échange direct de ressources entre
machines connectées, échange de programmes, de fichiers
(audio, vidéo ou autres)
la technique utilisée aujourd'hui est le système
décentralisé.Type gnutella, edonkey. La technique
utilisée par Napster est dite, centralisée.
Le peer-to-peer décentralisé
Le deuxième modèle, largement utilisé par
Gnutella (un autre pionnier des échanges de fichiers MP3),
repose sur des nœuds de réseaux, plutôt que
sur un serveur central : un système d'échange de
fichier totalement décentralisé. L'utilisateur du
logiciel se connecte via internet à l'ordinateur d'un ou
plusieurs autres utilisateurs, le tout constituant un réseau.
Par ce biais, chacun des utilisateurs met à disposition
de l'ensemble de la communauté une certaine partie des
fichiers de son ordinateur. Une requête lancée à
la communauté des utilisateurs sera communiquée
à l'ensemble des machines du réseau. Ce modèle
est plus difficile à utiliser que le premier, car les utilisateurs
finaux doivent trouver un nœud de départ sur le réseau
pour pouvoir se connecter. Sans cela, le réseau ne peut
pas être utilisé et un peer ne peut en trouver un
autre.
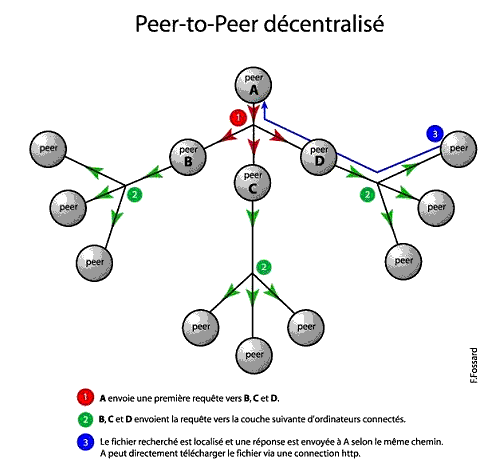
Le principe est le suivant : un ordinateur "A", équipé
d'un programme spécifique (baptisée par Gnutella
"servent", car il remplit les fonctions de client et
de serveur à la fois), se connecte à un ordinateur
"B", lui aussi équipé de ce programme.
"A" lui annonce ainsi qu'il est "en vie".
"B" relaie cette information à tous les ordinateurs
auquel il est connecté, "C", "D", "E"
et "F"… Ceux-ci relaieront l'information à
leur tour aux ordinateurs auxquels ils sont connectés,
et ainsi de suite avec tous les ordinateurs du réseau…
Une fois que "A" est reconnu "vivant" par
les autres membres du réseau de peers, il peut chercher
le contenu qui l'intéresse dans les répertoires
partagés des autres membres du réseau.
La requête sera envoyée à tous les membres
du réseau, en commençant par "B", puis
vers tous les autres membres. Si l'un des ordinateurs dispose
de ce fichier, il transmet l'information vers "A". Ce
dernier pourra ainsi ouvrir une connexion directe vers cet ordinateur
et télécharger le fichier. Ce modèle, en
étant décentralisé, est beaucoup plus robuste
qu'un modèle centralisé puisqu'il n'est pas dépendant
du serveur, point de défaillance potentiel d'un réseau.
Autre avantage : si l'un des utilisateurs se déconnecte
du réseau, le requête pourra être poursuivie
vers les autres ordinateurs connectés.
Le peer-to-peer assisté (Napster a cessé
d'exister en tant que partage de fichiers gratuits)
Le premier modèle, celui utilisé par Napster, emploie
un serveur central qui permet d'indexer les ordinateurs connectés
et les fichiers disponibles. Cet index est utile pour fournir
au client une cartographie des ressources disponibles : lorsqu'une
requête est effectuée, les peers peuvent communiquer
directement entre eux sans aucun besoin d'assistance du serveur.
Chaque fois qu'un utilisateur soumet une requête, ou recherche
un fichier particulier ; le serveur central crée une liste
de fichiers correspondant à la requête, vérifiant
dans la base de données du serveur les fichiers appartenant
aux utilisateurs connectés au réseau. Le serveur
central affiche cette liste, et le client peut ainsi sélectionner
les fichiers désirés depuis la liste et ouvrir une
connexion directe avec l'ordinateur individuel détenant
ce fichier. Le téléchargement se fait directement,
entre un utilisateur et un autre.
L'un des principaux avantages de ce modèle est l'index
central qui permet de localiser les fichiers rapidement et efficacement,
grâce à la base de donnée régulièrement
mise à jour du serveur. Par ailleurs, dans cette configuration,
tous les clients sont obligés d'être connectés
sur le réseau du serveur : la requête atteint donc
tous les utilisateurs connectés, ce qui rend la recherche
encore plus pertinente. Principal problème, en revanche
: ce type de système n'autorise qu'un seul point d'entrée
sur le réseau, et n'est pas à l'abri d'une panne
de serveur susceptible de bloquer toute l'application. Cette architecture
connaît une variante appelée peer-to-peer computing.
Celle-ci utilise la capacité de traitement des PC interconnectés
en mode peer-to-peer durant leur inactivité. Seti@home,
une application d'analyse des ondes radio spatiales en vue de
détecter d'éventuels messages extraterrestres, en
est le meilleur exemple.
|